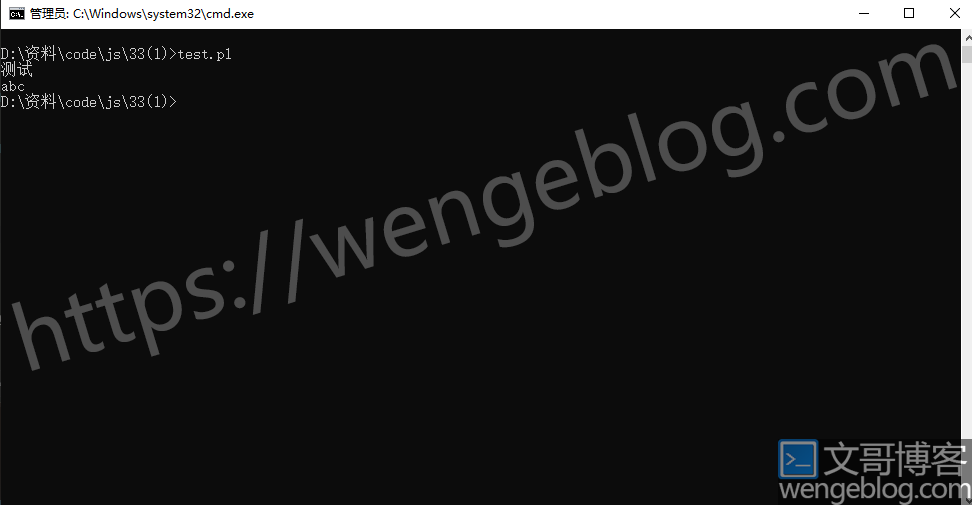
perl如何读取utf-8文本中文内容不乱码
前言
Win10后所有文本都是默认utf-8的编码,这种编码在读取中文时会乱码,不像linux已经支持了中文。所以Win10以后的文本类编程首先要解决的问题就是中文乱码问题。
在wsh的js中,可以直接以utf-8的形式读取到。但是perl不行,网上也没找到教程,chatgpt也解决不了。后来看到有一位博主的文章给了我启发。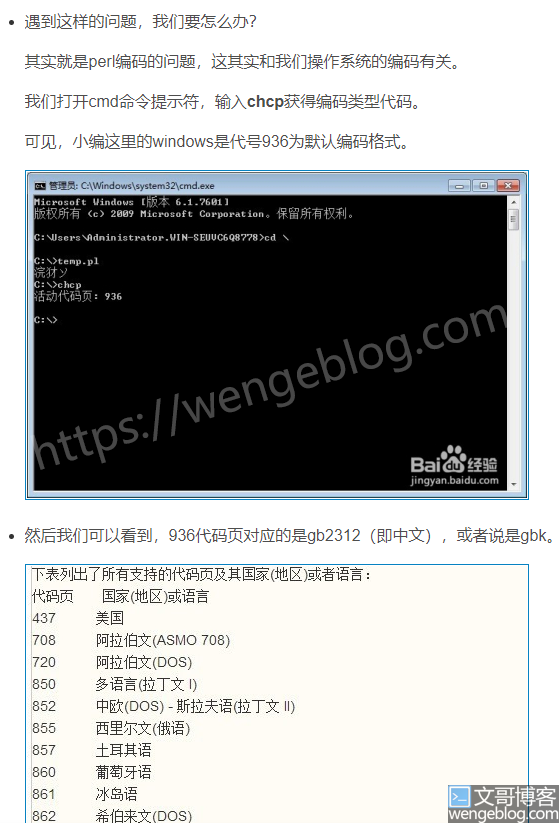
原理
虽然上面博主的代码也是无效的,但是我找到了方向。我很清楚的是在cmd环境中,编码是cp936,所以perl即使用utf-8的编码读取到了文本内容,输出到控制台时,也要再次转换为cp936,这样才会正确显示中文内容。
而chatgpt之所以也解决不了是因为它给的代码是符合系统默认的英文环境,不清楚中文系统控制台输出环境是用的cp936编码。
代码
1 | use utf8; |
可以看到成功输出中文和英文