python基于pytesseract的orc文字识别
前言
21年写过手机端的,当时是针对app的字体。这次难度加大,是手写的字体,在网上找了一些免费的根本识别不出来。想到pytesseract是免费还可以自己训练的,再来试试。
安装tesseract
最新版现在还是4.0的,官网我居然只看到3.x的版本。这个下载地址非官方。
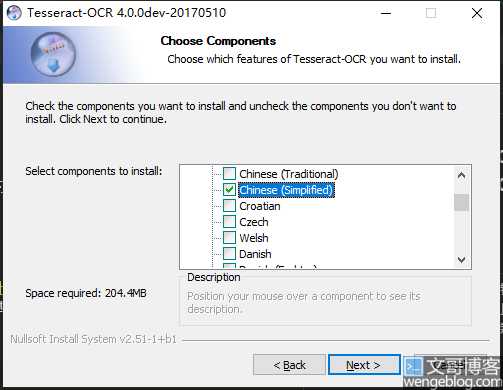
下载后直接安装,安装的时候顺便安装个简体中文语言包。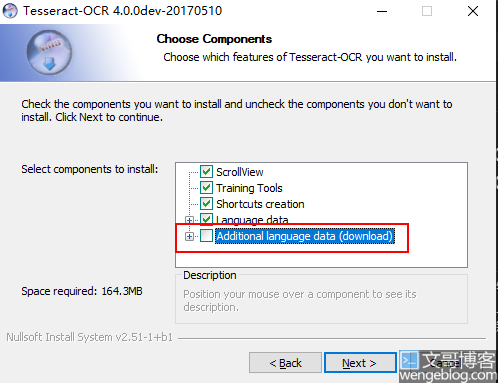
配置环境变量
默认安装路径为C:\Program Files (x86)\Tesseract-OCR,是没有配置环境变量的。
配置好后,运行tesseract -v,验证版本。tesseract 4.00.00alpha,4.0内部测试版,难怪官网没有4.0的安装包下载。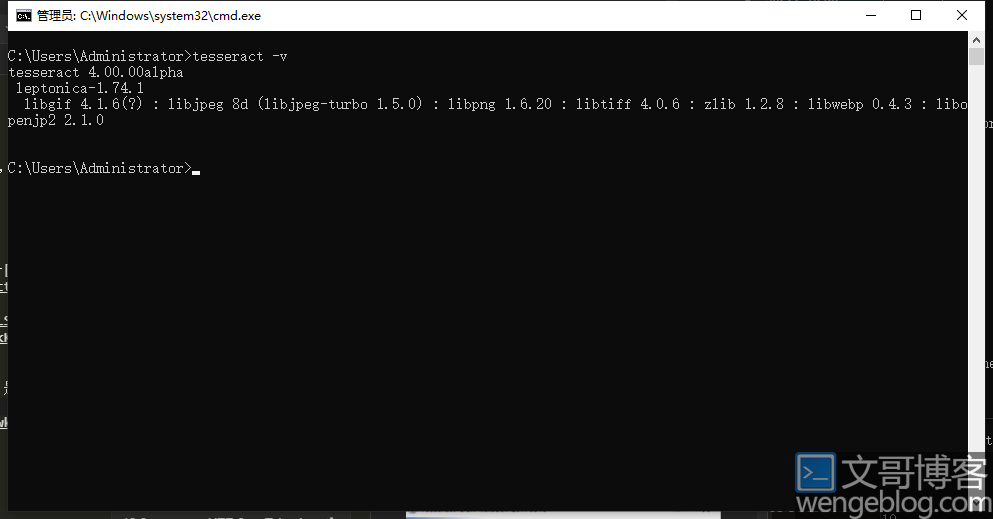
下载中文包
github下载
只需要中文简体这两个文件
然后复制到这个目录中
安装java jdk
官网下载安装包安装。
安装jTessBoxEditor
github里面安装jTessBoxEditor
支持中文语言包识别训练
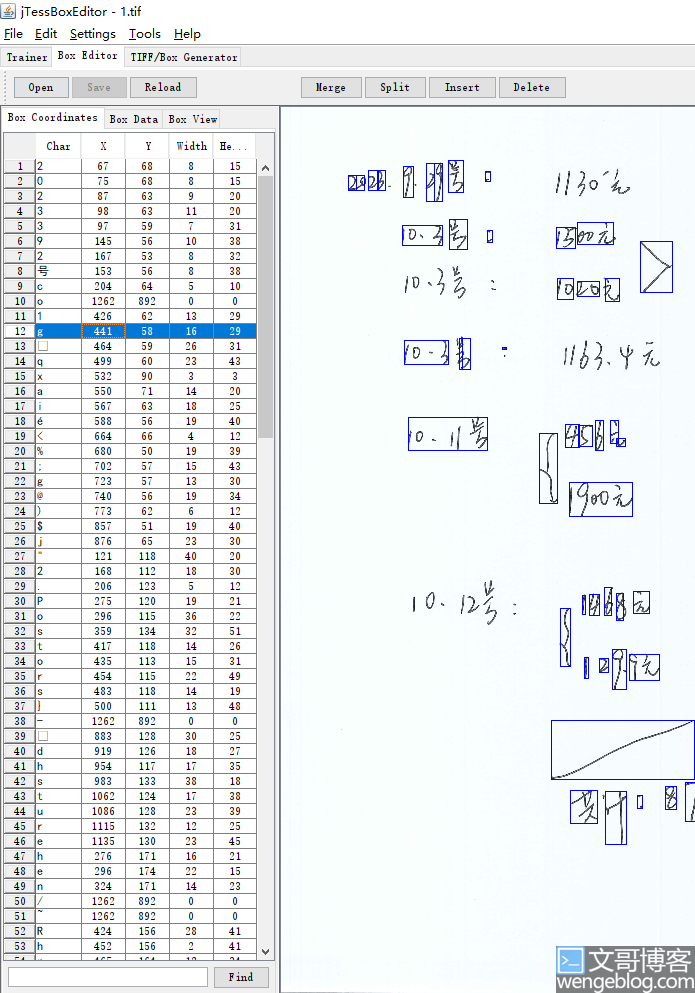
1 | tesseract 1.tif 1 -l chi_sim+eng batch.nochop makebox |
不带任何语言包识别
1 | tesseract 1.tif 1 batch.nochop makebox |
结论
tesseract不适合手写,手写还是用PaddleOCR这个库。一个个改意义不大。